- Матеріал з MachineLearning. (Перенаправлено з Crisp-dm ) CRISP-DM (CRoss Industry Standard...
- Інструменти методології
- Основні етапи проекту
- Розуміння бізнесу (Business Understanding)
- Розуміння даних (Data Understanding)
- Підготовка даних (Data Preparation)
- Моделювання (Modeling)
- Оцінка (Evaluation)
- Розгортання (Deployment)
- Історія
Матеріал з MachineLearning.
(Перенаправлено з Crisp-dm )
CRISP-DM (CRoss Industry Standard Process for Data Mining) найбільш поширена і популярна методологія ведення проектів інтелектуального аналізу даних [1] . Опитування, що проводилися в 2002, 2004 і 2007 роках, показують, що ця методологія часто застосовується дослідниками даних. [1] [1] [1]
Навіщо потрібна методологія?
Проекти аналізу даних повинні:
- надійно виконуватися випробуваними засобами з передбачуваними результатом (Reliable);
- бути повторюваними, особливо людьми з малим досвідом в аналізі даних (Repeatable).
Дотримання методикою дає нам:
- Засоби для збереження досвіду проектів, накопичений досвід дозволяє нам успішно повторювати проекти;
- Спрощення планування і управління проектами, відома і звична послідовність дій і набір необхідних артефактів;
- Простоту включення в роботу нових членів команди, зменшення залежності від "зірок".
Інструменти методології
ієрархічна декомпозиція
Застосування загальної моделі в конкретному проекті
База знань
(TODO: рекомендації по накопиченню бази знань)
У базі знань зберігаються добре зарекомендували себе методи для подальшого застосування в інших проектах.
Основні етапи проекту
CRISP-DM розбиває процес аналізу даних на шість основних етапів [1] :
Розуміння бізнесу (Business Understanding)
Перша фаза процесу спрямована на визначення цілей проекту і вимог з боку бізнесу. Потім ці знання конвертуються в постановку задачі інтелектуального аналізу даних і попередній план досягнення цілей проекту.
- Визначити бізнес цілі
- Оцінити ситуацію
- Визначити цілі аналізу даних
- Скласти план проекту
Розуміння даних (Data Understanding)
Друга фаза починається зі збору даних і ставить за мету познайомитися з даними якомога ближче. Для цього необхідно виявити проблеми з якістю даних такі як неправильний чи неповний, зрозуміти що за дані є в наявності, спробувати відшукати цікаві набори даних або сформувати гіпотези про наявність прихованих закономірностей в даних.
- Зібрати вихідні дані
- описати дані
- дослідити дані
- Перевірити якість даних
Підготовка даних (Data Preparation)
Фаза підготовки даних ставить за мету отримати підсумковий набір даних, які будуть використовуватися при моделюванні, з вихідних різнорідних і різноформатних даних. Завдання підготовки даних можуть виконуватися багато разів без будь-якого наперед заданого порядку. Вони включають в себе відбір таблиць, записів і атрибутів, а також конвертацію і очищення даних для моделювання.
- відібрати дані
- Очистити дані
- Зробити похідні дані
- об'єднати дані
- Привести дані в потрібний формат
Моделювання (Modeling)
У цій фазі до даних застосовуються різноманітні методики моделювання, будуються моделі та їх параметри налаштовуються на оптимальні значення. Зазвичай для вирішення будь-якої задачі аналізу даних існує кілька різних підходів. Деякі підходи накладають особливі вимоги на подання даних. Таким чином часто буває потрібен повернення на крок назад до фази підготовки даних.
- Вибрати методику моделювання
- Зробити тести для моделі
- побудувати модель
- оцінити модель
Оцінка (Evaluation)
На цьому етапі проекту вже побудована модель і отримані кількісні оцінки її якості. Перед тим, як впроваджувати цю модель, необхідно переконатися, що ми досягли всіх поставлених бізнес-цілей. Основною метою етапу є пошук важливих бізнес-задач, яким не було приділено належної уваги.
- оцінити результати
- Зробити рев'ю процесу
- Визначити наступні кроки
Розгортання (Deployment)
Залежно від вимог фаза розгортання може бути простою, наприклад, складання фінального звіту, або складною, наприклад, автоматизація процесу аналізу даних для вирішення бізнес-завдань. Зазвичай розгортання - це турбота клієнта. Однак, навіть якщо аналітик не бере участь в розгортанні, важливо дати зрозуміти клієнтові, що йому потрібно зробити для того, щоб почати використовувати отримані моделі.
- запланувати розгортання
- Запланувати підтримку і моніторинг розгорнутого рішення
- Зробити фінальний звіт
- Зробити рев'ю проекту
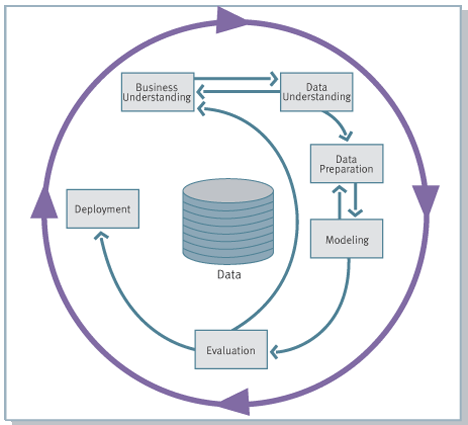
Переміщення вперед і назад між фазами - звичайна справа. Залежно від результату фази або її підзадачі приймається рішення, в яку фазу переходити далі. Стрілки, що показують найбільш важливі і часті переходи між фазами.
Зовнішнє коло символізує циклічну природу аналізу даних . Процес аналізу даних триває і після розгортання рішення. Знання, отримані під час процесу, можуть породити нові більш тонкі питання бізнесу. Подальший процес аналізу даних вигідно проводити, використовуючи знання, отримані раніше. [1]
Історія
Ідея CRISP-DM зародилася в 1996. У 1997 була розпочата розробка проекту в Європейському Співтоваристві під егідою фонду ESPRIT (European Strategic Program on Research in Information Technology). Проект очолили чотири компанії: ISL, NCR Corporation, Daimler-Benz і OHRA .
Ці компанії об'єднали свій досвід в проекті. ISL згодом була поглинена SPSS Inc. на той момент мала програмний продукт для аналізу даних Clementine. Комп'ютерний гігант NCR Corporation, що породив Teradata - СУБД для зберігання надвеликих даних, мав штат консультантів і власне програмне забезпечення по аналізу даних . У Daimler-Benz була велика команда інтелектуального аналізу даних для задоволення потреб власного бізнесу. Страхова компанія OHRA почала досліджувати потенціал інтелектуального аналізу даних.
Перша версія методології була випущена CRISP-DM 1.0 в 1999.
У липні 2006 консорціум анонсував бажання почати роботу над другою версією CRISP-DM. 26 вересня 2006, ініціативна група CRISP-DM зібралися для обговорення потенційних поліпшень в CRISP-DM 2.0 та подальшого плану робіт. Однак, цим починанням не судилося бути завершеними. З початку 2007 року ініціативна група більше не збиралася, вебсайт CRISP не оновлювався і не з'являлося будь-якої нової інформації.